Method
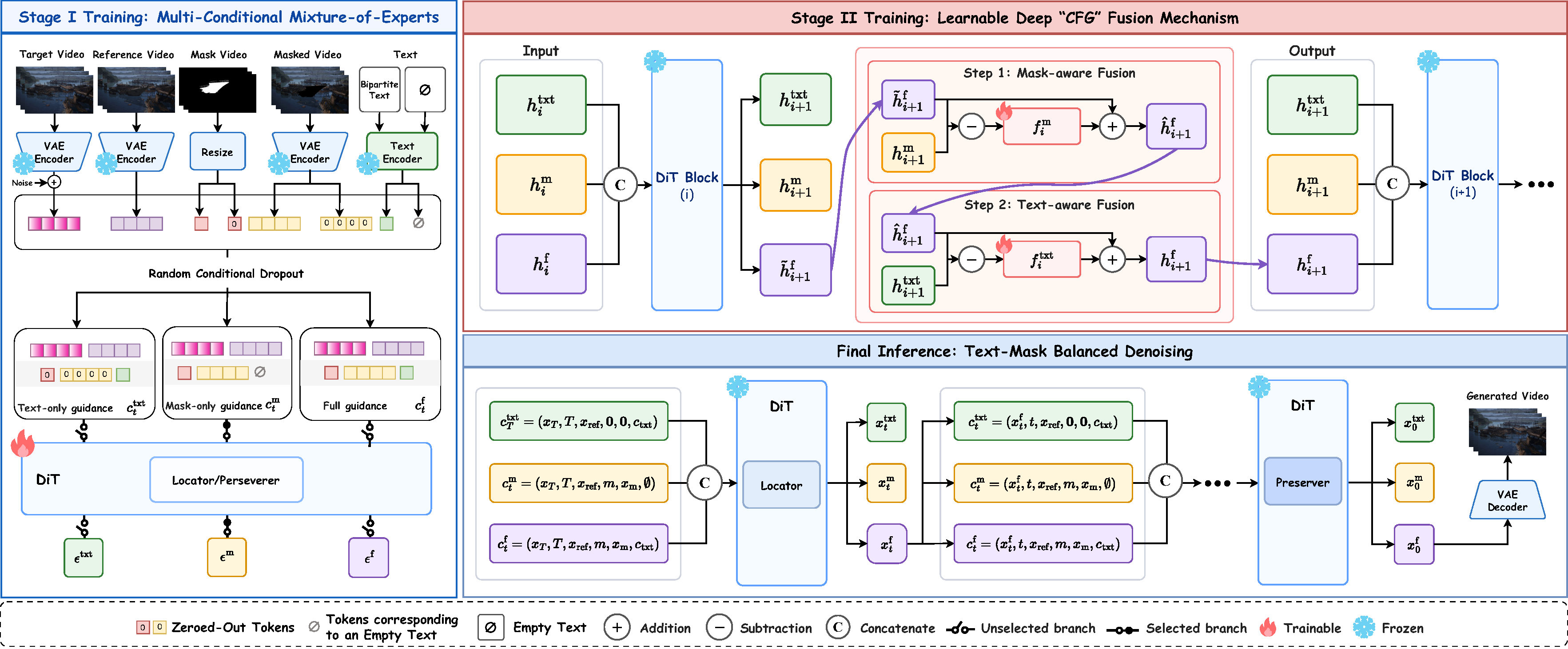
GenEraser is trained using a two-stage procedure, as illustrated in the Figure. The first stage trains the Multi-Conditional Mixture-of-Experts mechanism using random conditional dropout to enhance model alignment with mask and text conditions, thereby improving overall generalization. Subsequently, the second stage trains the Learnable Deep CFG Fusion module deterministically across three branches to balance the relative dominance of textual and mask guidance across diverse scenarios. Both the Locator and the Preserver follow this two-stage training procedure, while differing in their training configurations and injected noise levels. Finally, during inference, only the output corresponding to full guidance is utilized for subsequent denoising.